Mục lục nội dung
Nhắc lại về học có giám sát và không giám sát
Học có giám sát
Trong học máy, lớp các thuật toán học có giám sát Supervised learning là việc học các xác định hàm y = f(x) từ tập dữ liệu huấn luyện gồm $\{\{x_1, x_2, …, x_N\}; \{y_1, y_2,…, y_N\}\}$ sao cho $y_i ≅ f(x_i )$ với mọi i.
Để thực hiện điều này tập dữ liệu huấn luyện gồm các điểm dữ liệu trong đó mỗi điểm dữ liệu có chứa nhãn tương ứng.
Học không giám sát
Học cách xác định hàm y = f(x) từ tập dữ liệu huấn luyện gồm $\{x_1, x_2, …, x_N\}$. Các dữ liệu trong tập dữ liệu dùng để huấn luyện không có nhãn.
Các thuật toán phân cụm dựa trên tập dữ liệu chính là cách xác định cấu trúc ẩn trong tập dữ liệu đó.
Ví dụ về học không giám sát
Học không giám sát nhằm phân dữ liệu thành một số cụm cho trước.
Ví dụ phổ biến cho thuật toán này đó là việc phân loại khách hàng.
Giả sử ta có một tập dữ liệu mua hàng của các khách hàng, ta có thể đưa dữ liệu này vào thuật toán phân cụm để tiến hành phân loại khách hàng.
Các khách hàng có những đặc điểm tương đồng về mặt thông tin hoặc dựa trên lịch sử mua hàng, hành vi mua hàng có thể phân thành các loại khách hàng khác nhau.
Nói cách khác mỗi loại khách hàng sẽ có những đặc điểm chung giống nhau, và những đặc điểm đó được phát hiện thông qua thuật toán phân cụm mà chúng ta sẽ nghiên cứu ngay sau đây.
Ví dụ về K-means
Bạn đang đọc: 15. Thuật toán phân cụm K-Means
Ngoài ra có một ví dụ khác mà chúng ta cũng hay bắt gặp, đó là các mạng xã hội luôn tìm cách phân cụm những người có cùng sở thích, thói quen để đưa ra những gợi ý kết bạn hay tham gia một nhóm nào đó.
Để xác định được những người có các điểm tương đồng trong mạng xã hội ta cần một thuật toán phân cụm.
Bài toán phân cụm
Chúng ta sẽ xem xét lần lượt những nội dung tương quan đến bài toán phân cụm .
Khái quát bài toán phân cụm:
- Đầu vào: Tập dữ liệu không có nhãn
- Đầu ra: Các cụm dữ liệu đã được phân chia
Như vậy tiềm năng của bài toán phân cụm là những cụm tài liệu được phân loại bởi thuật toán. Chúng ta cùng xem xét đặc thù của một cụm .
Một cụm
- Trong một cụm thì các điểm dữ liệu thuộc về cụm đó phải giống nhau theo một ý nghĩa, việc xác định thế nào là giống nhau quyết định đầu ra của thuật toán này. Ví dụ như để xác định những khách hàng thuộc cùng một nhóm thì trước tiên ta cần phải xác định định nghĩa thế nào là giống nhau?
Hai khách hàng tương đồng có thể được xem xét dựa trên các tiêu chí khác nhau, có thể dựa trên số lần mua hàng, số tiền mua hàng, hay giới tính, độ tuổi… - Hai cụm dữ liệu là khác nhau: Điều này là cần thiết vì khi phân cụm các cụm phải là tách biệt nhau hoàn toàn, không có sự chồng lấp 2 cụm dữ liệu với nhau.


Một số phương pháp phân cụm phổ biến
- Phân cụm dựa trên phân vùng (Partition-based clustering): Đây là phương pháp phổ biến và được sử dụng nhiều trong các bài toán phân cụm. Mục tiêu là phân dữ liệu thành các phân vùng khác nhau.
- Phân cụm thứ bậc (Hierarchical clustering): Ngoài việc phân thành các cụm lớn, phương pháp này còn phân các cụm lớn thành những cụm nhỏ hơn dưới dạng thứ bậc.
- Mô hình hỗn hợp (Mixture models)
- Phân cụm sâu (Deep clustering): Sử dụng mạng nơ-ron học sâu để phân cụm.
Đánh giá chất lượng mô hình phân cụm
Để nhìn nhận chất lượng quy mô phân cụm ta hoàn toàn có thể nhìn nhận trải qua một số ít giải pháp như sau :
- Khoảng cách / sự khác biệt giữa hai cụm bất kỳ phải lớn. (khoảng cách giữa các cụm): Giữa các cụm phải được tách biệt nhau hoàn toàn và sự khác biệt giữa 2 cụm phải đủ lớn để phân biệt 2 cụm với nhau.
- Chênh lệch giữa các điểm dữ liệu bên trong một cụm phải nhỏ. Chênh lệch ở đây thể hiện sự khác biệt với nhau về mặt tương đồng giữa 2 dữ liệu theo tiêu chí phân cụm.
Thuật toán phân cụm K-means
Thuật toán phân cụm K-means được giới thiệu năm 1957 bởi Lloyd K-means và là phương pháp phổ biến nhất cho việc phân cụm, dựa trên việc phân vùng dữ liệu
Biểu diễn dữ liệu: $D = \{x_1, x_2, …, x_r \}$, với $x_i$ là vector n chiều trong không gian Euclidean. K-means phân cụm D thành K cụm dữ liệu:
- Mỗi cụm dữ liệu có một điểm trung tâm gọi là centroid.
- K là một hằng số cho trước.
Các bước trong thuật toán K-Means
- Đầu vào: Cho tập dữ liệu D, với K là số cụm, phép đo khoảng cách giữa 2 điểm dữ liệu là d(x,y)
- Khởi tạo: Khởi tạo K điểm dữ liệu trong D làm các điểm trung tâm (centroid)
- Lặp lại các bước sau đến khi hội tụ:
- Bước 1: Với mỗi điểm dữ liệu, gán điểm dữ liệu đó vào cluster có khoảng cách đến điểm trung tâm của cluster là nhỏ nhất.
- Bước 2: Với mỗi cluster, xác định lại điểm trung tâm của tất cả các điểm dữ liệu được gán vào cluster đó.
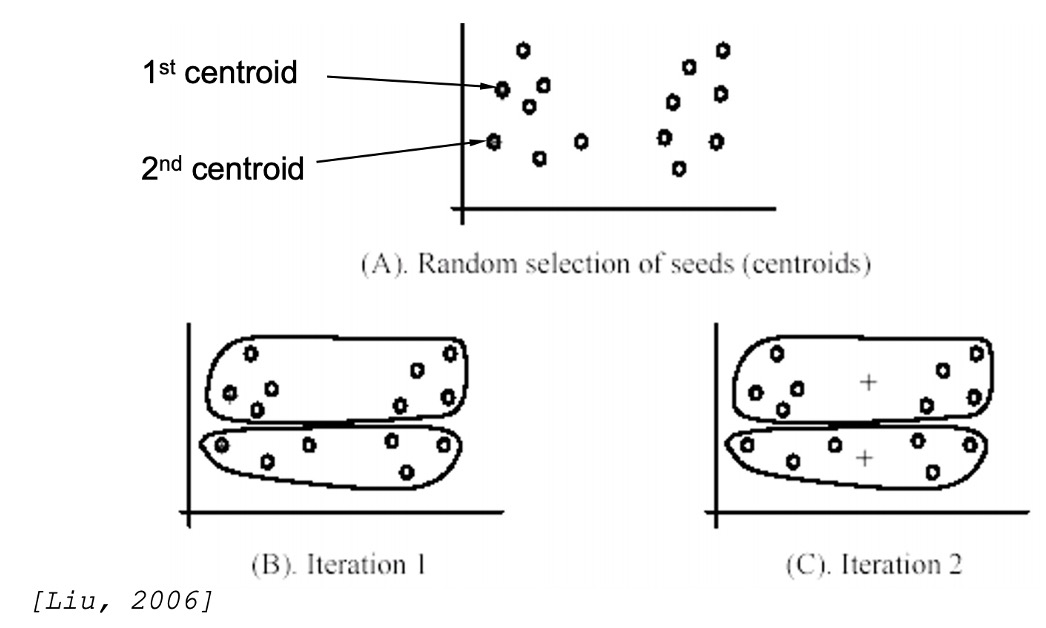
Sau đây là một số bước dưới dạng hình ảnh:
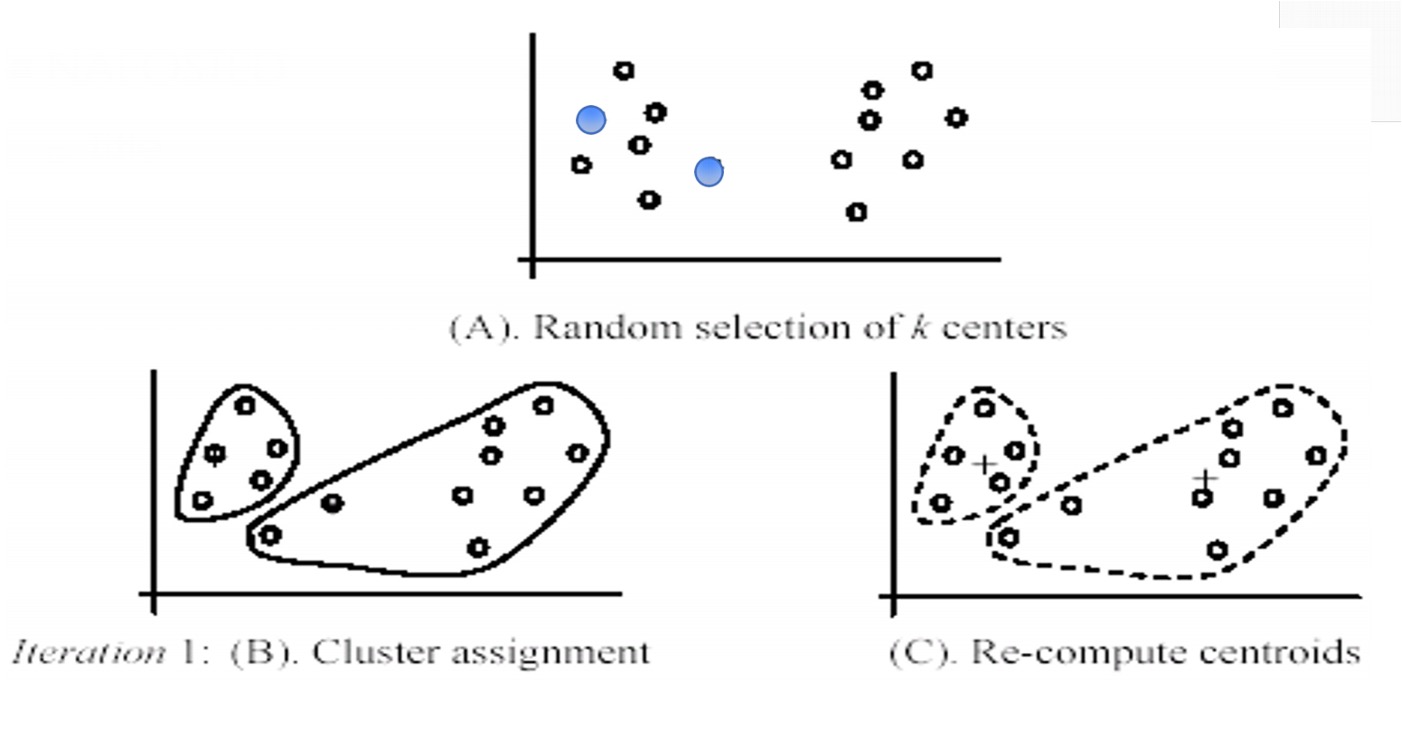
Tại bước này thuật toán sẽ khởi tạo k điểm dữ liệu trung tâm ban đầu, sau đó qua iteration 1 để thực hiện bước 1: gán các điểm dữ liệu vào cluster và bước 2: Xác định lại điểm trung tâm.
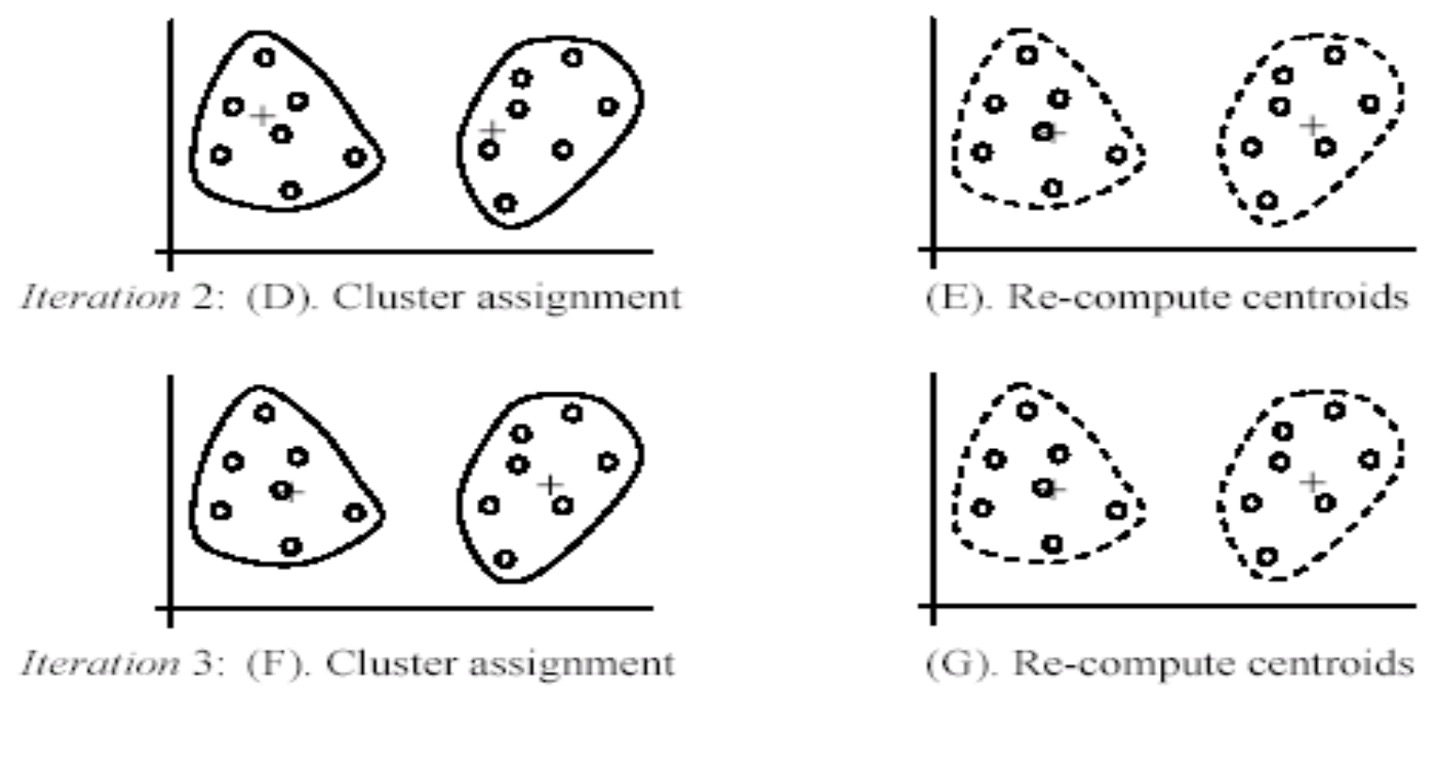
Các vòng lặp iteration 2 và iteration 3 tiếp tục thực hiện như vậy đến khi nào thuật toán hội tụ thì dừng lại.
Điều kiện hội tụ (điều kiện dừng thuật toán)
Ta sẽ xác lập điều kiện kèm theo dừng thuật toán theo 1 số ít cách như sau :
- Tại 1 vòng lặp: có ít các điểm dữ liệu được gán sang cluster khác hoặc
- Điểm trung tâm (centroid) không thay đổi nhiều hoặc
- Giá trị hàm mất mát không thay đổi nhiều:

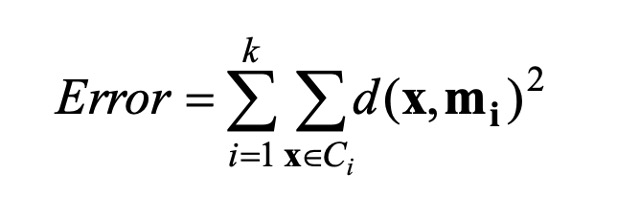
Trong đó USD C_i USD là cluster thứ i, USD m_i USD là điểm TT của cluster USD C_i USD tương ứng .
Nhìn chung về điều kiện kèm theo quy tụ hoàn toàn có thể thấy mối liên hệ giữa những điều kiện kèm theo là gần tương đương như nhau. Khi có ít điểm tài liệu được gán sang cluster khác hoàn toàn có thể khiến điểm TT không biến hóa nhiều và từ đó hàm mất mát cũng sẽ ít bị ảnh hưởng tác động. Vậy nên tất cả chúng ta hoàn toàn có thể sử dụng 1 trong 3 cách trên để xác lập điều kiện kèm theo dừng của thuật toán .
Xác định điểm trung tâm của cluster
Để xác định điểm trung tâm của cluster ta sử dụng công thức như sau:
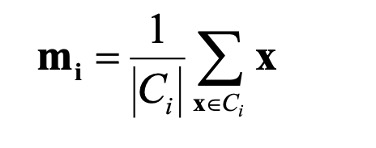
Trong đó USD C_i USD là cluster thứ i, USD m_i USD là điểm TT của cluster USD C_i USD tương ứng .
Phép đo khoảng cách
Trong K-means để nhìn nhận mức độ giống nhau hay khoảng cách giữa 2 điểm tài liệu ta hoàn toàn có thể sử dụng những phép đo khoảng cách khác nhau. Ngoài khoảng cách Euclidean, tuỳ thuộc vào từng bài toán hoàn toàn có thể sử dụng chiêu thức đo khác ( cosine, manhattan … )
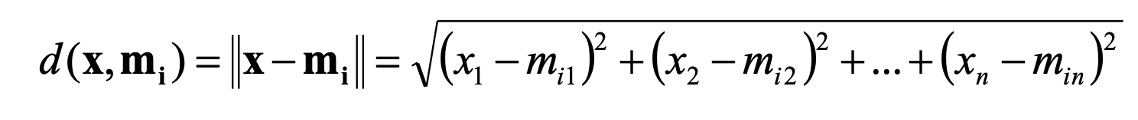
Mọi giải pháp tính khoảng cách giữa 2 vector đều hoàn toàn có thể được sử dụng. Mỗi cách tính khoảng cách biểu lộ cách nhìn nhận về tài liệu
- Có vô số cách tính khoảng cách
- Cách tính khoảng cách nào là tốt? Câu trả lời phụ thuộc vào từng bài toán để đưa ra cách tính khoảng cách phù hợp.
Một số ảnh hưởng đến thuật toán K-means
Chúng ta sẽ cùng nhau xem xét một số ít ảnh hưởng tác động đến thuật toán K-means và giải pháp để giải quyết và xử lý .
Ảnh hưởng của outlier
Outlier là gì?
Hiểu đơn thuần thì Outliers là một hoặc nhiều thành viên khác hẳn so với những thành viên còn lại của nhóm. Sự độc lạ này hoàn toàn có thể dựa trên nhiều tiêu chuẩn khác nhau như giá trị hay thuộc tính. Ví dụ về outlier hoàn toàn có thể như là nhiễu trong những cảm ứng hay lỗi trong quy trình nhập liệu của người dùng tác động ảnh hưởng đến chất lượng của tài liệu .
Xem xét ảnh hường
K-means nhạy cảm với những điểm outlier, ví dụ : Các điểm tài liệu outlier ảnh hưởng tác động lớn đến hiệu quả của việc phân cụm :
- Các điểm dữ liệu outlier có khoảng cách đến các điểm dữ liệu chuẩn rất lớn.
- Phân bố của các điểm outliner rất khác so với các điểm dữ liệu chuẩn
- Nhiễu hoặc lỗi của dữ liệu được thể hiện trong các điểm outlier
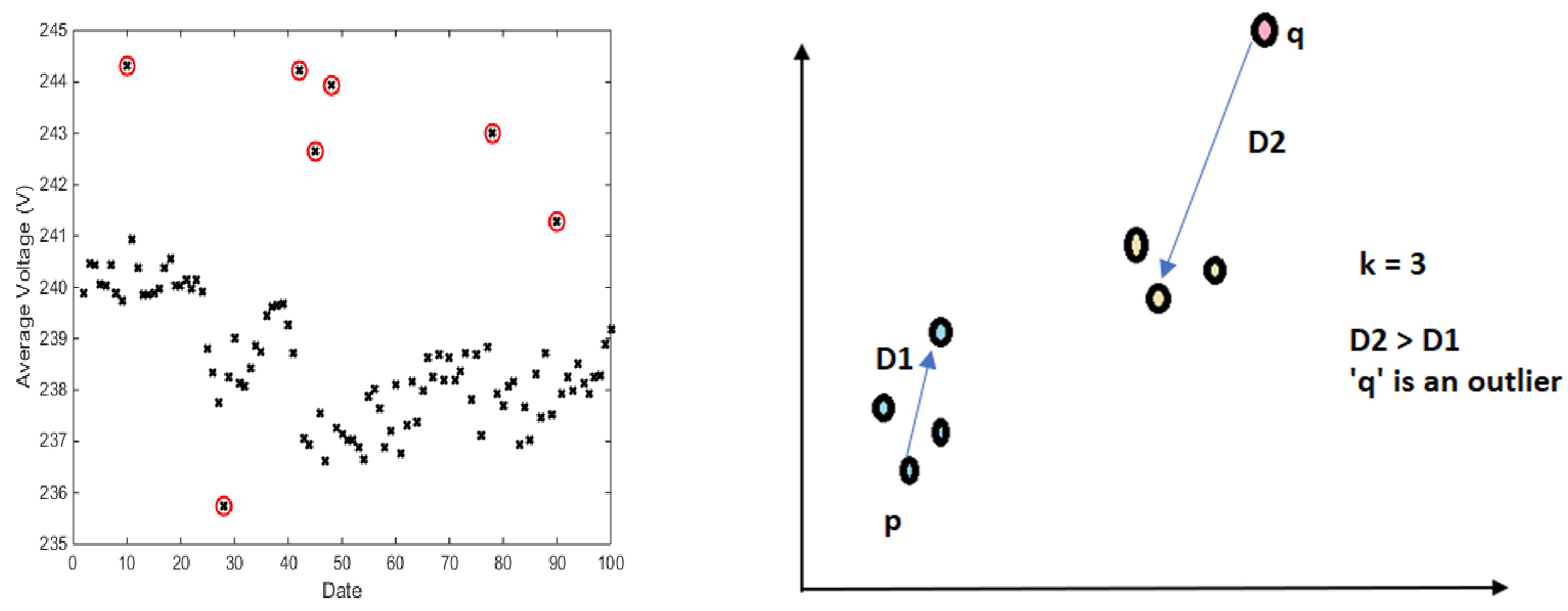
Khắc phục outlier
- Outlier removal: Có thể loại bỏ các điểm dữ liệu xa đáng kể so với điểm trung tâm (centroid) của các cluster so với các điểm dữ liệu khác. Việc loại bỏ có thể được thực hiện trước hoặc trong khi phân cụm.
- Random sampling: Thay vì phân cụm toàn bộ tập dữ liệu, chúng ta sẽ lấy ngẫu nhiên tập con S từ tập dữ liệu huấn luyện. S được sử dụng để phân cụm, tập S lúc này sẽ có ít các điểm outlier hơn tập dữ liệu gốc. Sau khi phân cụm xong, tập dữ liệu còn lại sẽ được gán vào các cụm đã học được
Ảnh hưởng của việc khởi tạo trung tâm
Chất lượng của K-means phụ thuộc vào việc khởi tạo các điểm centroid
Giải pháp 1: Lặp lại nhiều lần thuật toán K-means:
- Mỗi lần chạy lại thuật toán K-means sẽ khởi tạo các điểm centroid khác nhau
- Sau quá trình học, tiến hành gộp các kết quả từ các lần chạy thành kết quả cuối cùng
Giải pháp 2: Thuật toán K-means++ : Để tìm ra cụm tốt nhất, chúng ta có thể lần lượt khởi tại các điểm trung tâm từ tập D tuần tự như sau:
- Lấy ngẫu nhiên điểm centroid đầu tiên m1
- Lấy điểm centroid tiếp theo là điểm xa nhất so với m1
- ..
- Lấy điểm centroid thứ i $(m_i)$ là điểm xa nhất so với $\{ m_1,…, m_i-1\}$
- …
- Bằng cách này K-means sẽ hội tụ về gần kết quả tối ưu (Arthur, D.; Vassilvitskii, 2007)
Tổng kết
Ưu điểm của thuật toán K-means:
* Đơn giản
- Hiệu quả trong thực tế
- Đảm bảo hội tụ trong thời gian đa thức [Manthey & Röglin, JACM, 2011]
- Linh hoạt trong việc lựa chọn phương pháp đo khoảng cách
Hạn chế:
- Việc lựa chọn các tính khoảng cách cho bài toán cụ thể khó.
- Nhạy cảm với các điểm dữ liệu outlier
Code Python
Load những thư viện thiết yếu
1 2 3 4 5
from __future__ import print_function import numpy as np import matplotlib.pyplot as plt from scipy.spatial.distance import cdist np.random.seed(20)
Khởi tạo tài liệu demo
1 2 3 4 5 6 7 8 9 10 11
# Khởi tạo tài liệu demomeans = [ [2, 2], [9, 3], [3, 6] ] cov = [ [1, 0], [0, 1] ] N = 500 X0 = np.random.multivariate_normal(means[0], cov, N) X1 = np.random.multivariate_normal(means[1], cov, N)object X2 = np.random.multivariate_normal(means[2], cov, N) X = np.concatenate( (X0, X1, X2), axis = 0) K = 3 original_label = np.asarray( [0]*N + [1]*N + [2]*N) .T
1 2 3 4 5 6 7 8 9 10 11 12 13
def kmeans_display(X, label) :
K = np.amax(label) + 1
X0 = X[label = = 0, : ]
X1 = X[label = = 1, : ]
X2 = X[label = = 2, : ]
plt.plot(X0[ :, 0], X0[ :, 1], ' b ^ ', markersize = 4, alpha = .8)
plt.plot(X1[ :, 0], X1[ :, 1], ' go ', markersize = 4, alpha = .8)
plt.plot(X2[ :, 0], X2[ :, 1], ' rs ', markersize = 4, alpha = .8
)
plt.axis(' equal ')
plt.plot( )
plt.show( )
1
kmeans_display(X, original_label)
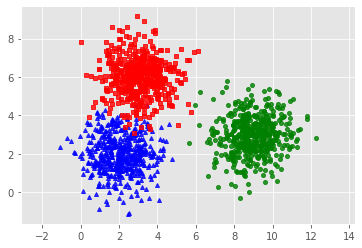
Biểu diễn dữ liệu demo
Xây dựng những hàm thiết yếu
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25
def init_centroids(X, k) :
# pick k centroid randomly return X[np.random.choice(X.shape[0], k, replace=False) ]
def assign_labels(X, centroids, k) :
clusters = { }
for i in range(k) :
clusters[i] = [ ]
for featureset in X:
distances = [np.linalg.norm(featureset - centroid) for centroid in centroids]
cluster = distances.index(min(distances) )
clusters[cluster] .append(featureset)
return clusters
def update_centroids(clusters) :
new_centroids = [ ]
for cluster, data_points in clusters.items( ) :
new_centroids.append(np.average(data_points,axis=0) )
return new_centroids
def has_converged(centers, new_centers) :
# return True if two sets of centers are the same return (set( [tuple(a) for a in centers] ) = =
set( [tuple(a) for a in new_centers] ) )
Phần code tiến hành thuật toán
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
max_iter = 10
k = 3
centroids = init_centroids(X, k)
for i in range(max_iter) :
clusters = assign_labels(X, centroids, k)
new_centroids = update_centroids(clusters)
if has_converged(centroids, new_centroids) :
print(' convered ')
break
centroids = new_centroids
X_ = [ ]
labels = [ ]
for cluster, datapoints in clusters.items( ) :
for datapoint in datapoints:
X_.append(datapoint)
labels.append(cluster)
Hiển thị tác dụng
1
kmeans_display(np.array(X_), np.array(labels
) )
Kết quả thuật toán
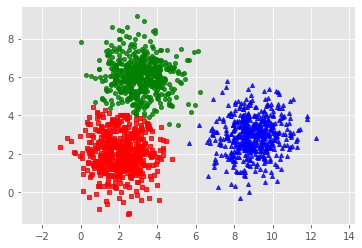
Biểu diễn kết quả phân cụm của thuật toán
Source: https://mindovermetal.org
Category: Ứng dụng hay